关于编码的那些事儿

最近,新的新闻系统启用了,大家遇到了不少页面乱码的问题。这篇博客会给大家讲解网页编码的详细原理,帮助大家理清思路,从而能有效地解决工作中遇到的乱码问题。
编码的故事
先来个生动的例子讲解一下网页的编码究竟是什么东东,以及编码在哪些环节会产生影响。我们平常会接触到的网页编码有两种,GBK(注:GBK 其实是 GB2312 的一个超集,下面都先以 GBK 来代表它们) 和 UTF-8。这里,可以把我们的网页想象成碟片,GBK 是音乐 CD,而 UTF-8 是影片 DVD。碟片就是我们写的网页,它有自己的编码格式,有 CD(GBK) 和 DVD(UTF-8) 两种。然后,存放网页的服务器,则可以想象成碟片贩子。假设碟片都是没有任何标签的(网页没被解析其实是个黑盒),它是什么格式,只有碟片贩子知道。我们去买碟片时(请求服务器),只能从贩子(服务器)那里获知碟片是什么碟(是 CD 还是 DVD)。然后,碟片买回家后,用播放机(浏览器)播放碟片(网页),我们会根据贩子(服务器)给我们的信息,来选择用 CD(GBK)还是用 DVD(UTF-8)解码播放。如果这个过程里出现了差错,就会导致播放不成功(乱码)了。后来,大家觉得这种方式还是不太稳妥,于是又给碟片上个包装(meta 信息),标明是 CD (charset="GBK")还是 DVD(charset="UTF-8")。
好吧,例子还是不太生动,编不下去了,不过希望能给大家有个概念。
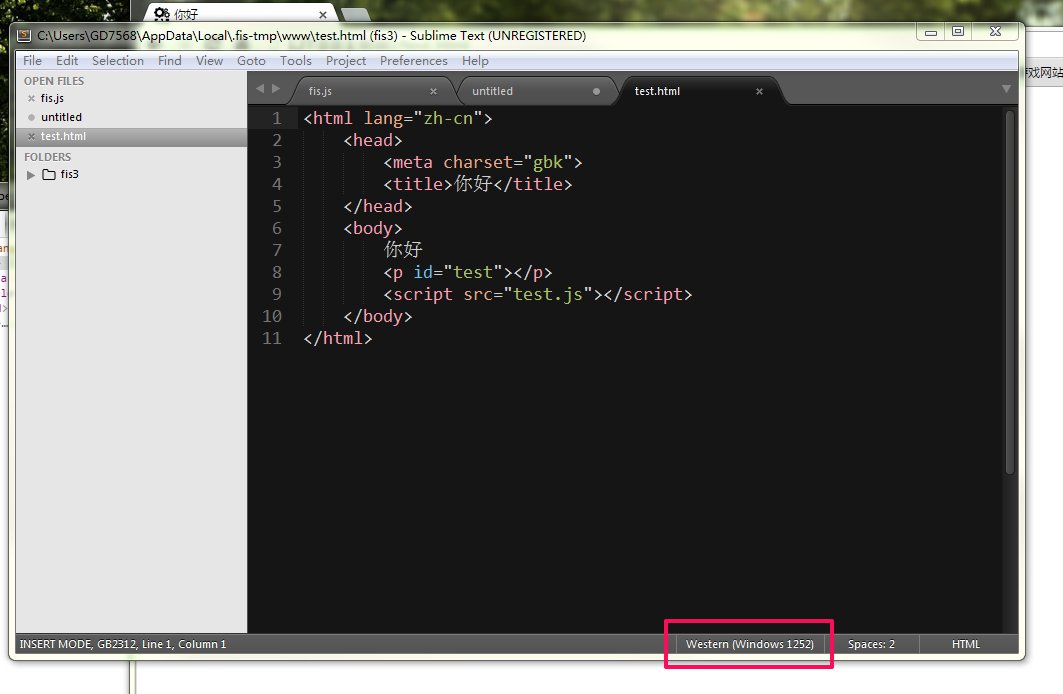
网页的编码,其实在我们保存文件的时候,就已经确认了。我们用编辑器(例如 Sublime)打开网页文件,其实是可以看到网页文件的真实编码的。对于 Sublime,需要在配置文件设置 "show_encoding": true。如图所示,这个其实就是网页的真实编码了(注:因为 Sublime 其实原生不支持 GBK 的,这里显示的 Windows 1252 其实就是 GBK 啦)。
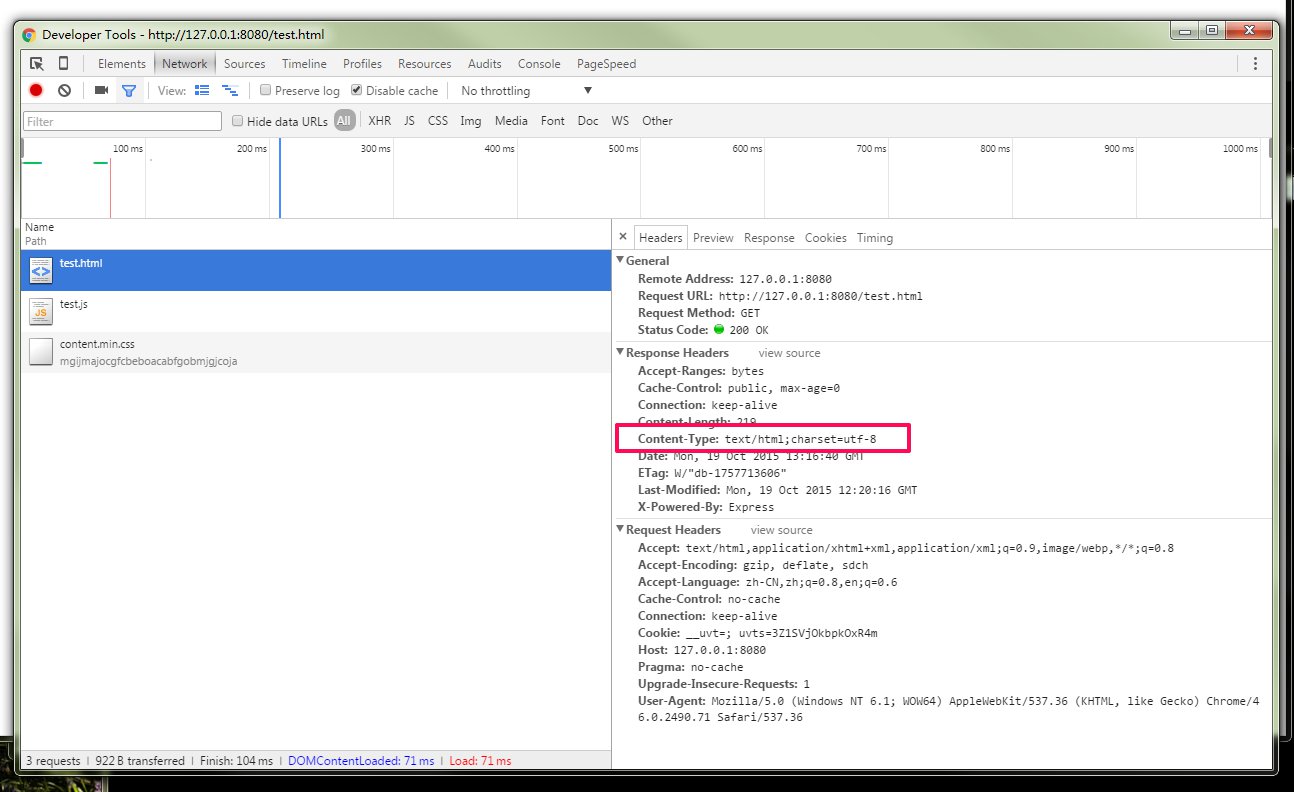
产生乱码,其实就是网页的解码过程出现了问题。那么,网页的解码是由什么因素决定的呢?首先,很显然,跟它自身的编码是完全没关系的。道理也很简单,一张碟片能不能播放正确,显然跟它是什么格式是没有关系的,而是人们怎么去处理它。好了,不卖关子了,决定网页解码的第一关键要素,是浏览器。我们可以从浏览器菜单可以选择网页的编码,从而让浏览器以什么样的编码去解析网页。坑爹啊,我不可能每打开一个网页都选一次吧。没错,所以一般浏览器都是设置成自动识别的。那么,决定浏览器自动识别编码的第一要素是啥呢?答案是服务器。服务器返回网页给浏览器,在 http 返回的头部,可以带有 charset 信息,这个 charset 信息,是存放在 Content-Type 属性里的。如下图。
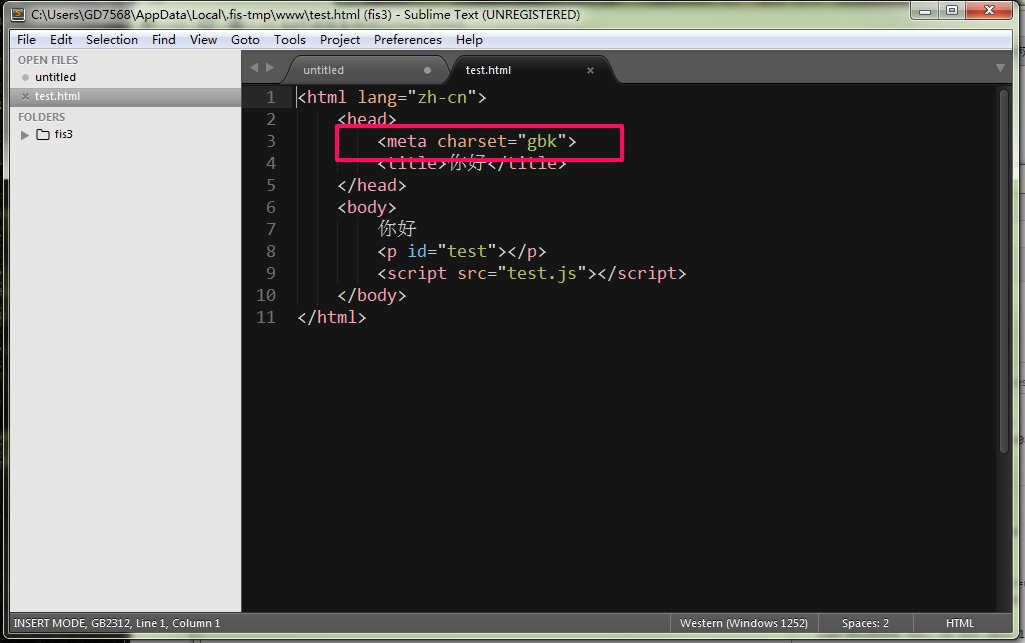
注意,刚刚说的,http 返回头是可以带有 charset 信息,所以,也就是可以不带了。卧槽,这碟片贩子太不负责任了!还好,碟片有包装,我们还是可以知道是什么碟子。决定浏览器自动识别编码的第二要素,是网页 head 里的 <meta charset="xxx">。很多同学,以为这个 meta 信息决定了网页的编码,这是个很错误的理解。重复一下,决定网页编码,是在你保存文件选择格式时发生的(录制碟片),而这个 meta 信息,只是个告诉浏览器的信息(只是个包装)。所以,当浏览器发现 http 返回头没有 charset 信息时,就会去找 meta 里的 charset 信息。如下图。
如果这个碟片(网页)连包装(meta 信息)都木有,那会怎么样呢?这时,浏览器会根据自身内部机制去选取一种编码来解码页面。显然,这是完全不可控的。因为不同的系统(Win、Android、iOS、Mac),不同的系统语言(中文、英文),不同的浏览器(IE6、7、8、9、10、11、Chrome、FireFox、Safari),这些不同再组合出不同三次方的组合,会有不同的行为(其实就两种结果:乱码和正确)。当然,这是我们不希望看到的情况。
课间小结
- 网页的编码是网页文件自身决定的,是我们保存的时候完成编码的,和
<meta charset="xxx">没有关系的。 - 浏览器自动选择编码的优先级:http 返回头
Content-Type><meta charset="xxx">> 浏览器内部机制
新的新闻系统干了什么?
其实,乱码和新的新闻系统是没啥太大关系的,只是新的新闻系统为了推行 UTF-8(这是好事),把服务器的 http 返回头 Content-Type 里的 charset 给去掉了。在这之前,我们服务器的 http 返回头的 Content-Type,一直是带着 charset=GB2312 的,也就是,浏览器访问我们的网页,会自动选择成 GBK 编码。
为什么 http 返回头要去掉 charset?
答:这是一个兼容新(UTF-8)旧(GBK)的折中方案,把浏览器自动选择编码的抉择权,交到网页里的 <meta charset="xxx"> 身上。因为这次升级,并没有把旧的网页文件转换成 UTF-8 编码(注意,是自身编码,非 meta 信息),所以假如在返回头里加上 charset=utf-8 的话,旧的网页就会全部乱码了。
为什么会有乱码情况?
答:因为有的网页没有设置 meta 的 charset 信息,所以浏览器就任性地随意解码了,于是就会有乱码情况出现了。
include 的文件没有得设置 meta,浏览器会不会任性?
答:不会。所谓的 include,是在服务器上完成的。举栗子,include 就是碟片里的一个片段,可以是音乐,也可以是视频,在碟片贩子(服务器)卖给我们之前,就已经封好在碟片(网页)里面了。至于它是什么内容,自然也由碟片的标签包装信息(meta)来标示了。
为什么我引用的网页还是乱码?
答:这个要看具体场景。如果你是用 iframe 或者 Ajax 方式引入网页,那么是有可能引起乱码的。
CSS 和 JS
我们已经了解了 HTML 的编码,那么 CSS 和 JS 呢?CSS 和 JS 文件本身的编码,显然地,也是在保存的时刻决定的。那么解码呢?下面来说说。
CSS 的 @charset 是否有用?
答:有,不过作用甚微。对于 CSS 文件,浏览器还是优先判断 http 返回头 的 Content-Type。所以,我们以前的情况,http 返回头是带有 gb2312 的,但我们还用 @charset,其实是没什么卵用的。
JS 难道也是 http 返回头决定?
答:错,然而并不是。JS 的解码,首先是由 script 标签的 charset 控制的,如果 script 标签没有 charset,那么就由 HTML 的 meta charset 控制,和 http 返回头是木有任何关系的。
Ajax 请求的 CSS 和 JS 呢?
答:已经用到 Ajax 来加载 CSS 和 JS 了,很高大上哦。对于这种场景,首要抉择条件,还是 http 返回头的 Content-Type charset,如果 http 返回头 Content-Type 里没有指定 charset,则使用 UTF-8 编码。这里,我们要确保 CSS 和 JS 本身文件的编码是和上述的情况是一致的,才能避免乱码情况。Ajax 请求 HTML 和 JSON 数据也是同理。Ajax 请求的场景,和网页本身的编码,是没有关联的。
举个例子吧,假如网页是 GBK 编码,但 JSON 的 http 返回头 Content-Type 并没有指定 charset,那么,这个 JSON 文件必须用 UTF-8 编码,才能避免乱码。
这里要注意,Ajax 请求 JS,和动态插入 script 标签,是完全不一样的两回事哦。我们平时跨域用的 JSONP,其实是动态插入 script 标签,而并非 Ajax。Ajax 是用 XMLHttpRequest 对象做异步通信。所以,我们用 Ajax 的时候,是看 http 返回头 的 Content-Type charset,但用 JSONP 的时候,就要看 script 标签的 charset 和网页的 meta charset了(和上述 JS 解码一个道理)。
课间小结
- CSS 和 JS 的编码,都是在保存的时刻选择决定。
- CSS 的解码优先级:http 返回头 Content-Type > @charset
- JS 的解码优先级:script 标签的 charset 属性 > meta 标签的 charset 属性。JS 的解码和 http 返回头没有关系。
- Ajax 请求的资源(CSS、JS、JSON、HTML),由 http 返回头 Content-Type charset 决定编码。如果没有指定,则使用 UTF-8。
- Ajax 和 JSONP 是完全不同的两回事,JSONP 只是动态插入 script。
最佳实践
确保编码和解码的一致性
避免乱码,最主要的,还是要确保编码和解码的一致性。通过上面的内容,我们学习到,http 返回头 Content-Type 里的 charset 对浏览器的解码起了很重要的作用,所以,我们必须确保保存文件时选择的编码,和 http 返回头 charset 是一致的。然后,次要的因素,HTML meta 里的 charset 和 script 标签里的 charset,也要确保和文件本身编码一致。
对于 HTML
使用 HTML5 的 doctype,然后 meta charset 必须添加在 head 里的最前位置,如下代码所示。
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="utf-8">
<title>你好</title>
</head>
<body>
你好
</body>
</html>
旧的 meta 指定方式 <meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />,必须唾弃。
对于 CSS
唾弃 @charset。
对于 CSS 中 font-family 出现的中文字体,使用 Unicode 或者英文来标示。
| 字体名称 | 英文名称 | Unicode 编码 |
|----------|-------------------|------------------------|
| 宋体 | SimSun | \5B8B\4F53 |
| 黑体 | SimHei | \9ED1\4F53 |
| 微软雅黑 | Microsoft YaHei | \5FAE\8F6F\96C5\9ED1 |
对于 JS
使用和 HTML 一样的编码,尽量不要在 script 标签里用 charset 属性来指定。
对于 Ajax
确保 Ajax 请求的文件的编码和 http 返回头 charset 是一致的。如果返回头没带 charset,则使用 UTF-8。注意,这里说的只是 Ajax GET 请求的情况,并不适用于 POST 情况。
对于 JSONP
平台给的 JSONP 接口,都是用 unicode 编码返回的,所以我们基本不用担心乱码。如果自行实现的 JSONP,则需要注意 JSONP 数据和网页 meta charset 要确保编码一致。不过,jQuery 可以修改 JSONP 返回插入 script 标签的 charset 值。例子如下。
$.ajax({
url: 'xxx',
dataType: 'jsonp',
scriptCharset: 'gbk',
}).done(successCallback);
补充
FIS
对于我们前端生成的 HTML、JS、CSS、JSON 等资源,因为我们是使用 FIS 构建的,所以产出的文件的编码,其实是由 FIS 的配置确定的,而不是我们编辑时选择保存决定的。
GBK 的 JS 资源上线后变成了 UTF-8
这是个比较奇怪的情况。之前有同事遇到,因为资源的路径多了一个 /,引出了这个事故。后来查了一下,估计这个是服务器那边的配置导致的。因为我们请求的文件,都是服务器返回的,这个过程,服务器是可以对文件进行修改的。所以,我们要仔细检查出问题的资源的路径是否完全正确,特别是有没有多了一个 / 这样的情况。
手机阅读请扫描下方二维码:
①請問在做新的頁面的時候,還未上線如何知道http 返回头 Content-Type 的值呢?
②sublime里右下腳顯示的encoding是文件的真實編碼還是meta的值呢?我直接修改meta的值右下腳的顯示會跟著變的..
1
555
1
1
1
1
1
1
1
1
1
1
1
1
1
0KeeTeam
555
555
0KeeTeam
555
0KeeTeam
0KeeTeam
0KeeTeam
zoifgqnouflvkbkulmjt
test
test
%{44329*42245}
test
1











































1











































1











































1











































1











































1











































1











































1











































1











































1











































1











































1











































1











































1











































1











































1











































1
1
1
555
1
1
1
1
1
1
555
1
555
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
admin